







Necessary Package Installation
For the project here, we will require to install Selenium together with some other packages.
Reminder: For this project, we will use a Mac.
For installing Selenium, you just need to type following in the terminal:
pip install selenium
For managing a webdriver, we would utilize a webdriver-manager. You could utilize Selenium for controlling most well-known web browsers like Internet Explorer, Firefox, Chrome, Opera, and Safari. We would be utilizing Chrome.
pip install webdriver-manager
After that, we would also require Selectorlib to download and parse the HTML pages we route to:
pip install selectorlib
Set Up an Environment
After that, make a new folder on the desktop as well as add a few files.
$ cd Desktop $ mkdir amazon_scraper $ cd amazon_scraper/ $ touch amazon_results_scraper.py $ touch search_results_urls.txt $ touch search_results_output.jsonl
You would also require to place the file called “search_results.yml” in a project directory. The file would be utilized later for grabbing data for every product on a page through CSS selectors. You could find a file here.
After that, open the code editor as well as import following in amazon_results_scraper.py file:
from selenium import webdriver from webdriver_manager.chrome import ChromeDriverManager from selenium.common.exceptions import NoSuchElementException from selectorlib import Extractor import requests import json import time
Then, make a function named search_amazon, which take a string for items we need to search on Amazon like an input:
def search_amazon(item):
#we will put our code here.
With webdriver-manager, it’s easy to install a right version of ChromeDriver:
def search_amazon(item):
driver = webdriver.Chrome(ChromeDriverManager().install())
Load a Page and Choose Elements
Selenium offers many techniques for choosing page elements. We could choose elements by name, ID, XPath, class name, link text, tag name, as well as CSS Selector. Also, you may use qualified locators for targeting page elements related to other elements. For different objectives, we will utilize ID, XPath, and class name. Let’s load an Amazon homepage. Below the driver element, type these following:
driver.get('https://www.amazon.com')
After that, open Chrome as well as navigate to Amazon homepage, we require to get locations of page elements required to cooperate with. For different objectives, we need to:
- Input name of item(s) that we wish to search into a search bar.
- Then, click on search button.
- Navigate a result page for item(s).
- Repeat through resulting pages.
Then, right click on a search bar as well as from a dropdown menu, you need to click on inspect. It will take you to the section called browser developer tools. After that, click the icon:
Hover on a search bar and click search bar for locating the elements in DOM:
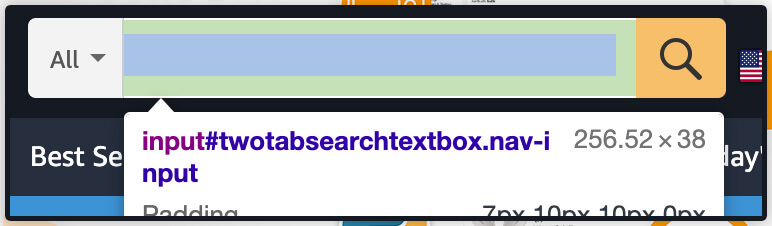
Its search bar is the ‘input’ element having id of “twotabssearchtextbox”. We could interact with the items using Selenium through using find_element_by_id() technique, then send the text input in it through binding .send_keys(‘text that we wish in a search box’) including:
search_box = driver.find_element_by_id('twotabsearchtextbox').send_keys(item)
Then, let’s repeat similar steps we have taken to get a location of a search box with magnifying a glass search button:

For clicking on the items having Selenium, we initially require to choose an item and chain .click() for end of a statement:
search_button = driver.find_element_by_id("nav-search-submit-text").click()
After we click search, we need to wait for a website to load the initial page of the results or we would get errors. You might utilize:
import time time.sleep(5)
However, selenium has an in-built method for telling a driver to wait for any particular amount of time:
driver.implicitly_wait(5)
As the hard part comes, we wish to discover how many result pages we get, as well as repeat through every page. Many elegant ways are there to do that, however, we would utilize a quick solution. We will locate an item on a page, which shows total results and choose it with its XPath.
Here, we can observe that total result pages are shown in a 6th list element (<li> tag) about the list having a class “a-pagination”. Just for fun, we will position two selections within a try or except block: having one for an “a-pagination” tag, as well as if for whatsoever reason which fails, we would choose an element underneath that with a class called “a-last”.
While using Selenium, one common error comes is a NoSuchElementExcemtion that is thrown while Selenium just cannot get a portion on the page. This might happen in case, an element hasn’t loaded or in case, the elements’ position on a page changes. We could catch that error as well as try and choose something else in case, our initial option fails because we utilize a try-except:
try:
num_page = driver.find_element_by_xpath('//*[@class="a-pagination"]/li[6]')
except NoSuchElementException:
num_page = driver.find_element_by_class_name('a-last').click()
Now, it’s time to make the driver wait for some seconds:
driver.implicitly_wait(3)
We have chosen an element on a page, which shows total result pages, as well as we wish to repeat through each page, collecting current URL for the list, which we would later feed into another script. It’s time to use num_page, get text from an element, cast that like an integer, as well as put that into ‘a’ to get a loop:
url_list = []
for i in range(int(num_page.text)):
page_ = i + 1
url_list.append(driver.current_url)
driver.implicitly_wait(4)
click_next = driver.find_element_by_class_name('a-
last').click()
print("Page " + str(page_) + " grabbed")
When we get the links of result pages, tell a driver to leave:
driver.quit()
Recollect a ‘search_results_urls.txt’ file that we had made earlier? We will require to open that from a function within ‘write’ mode and place each URL from an url_list to that on a completely new line:
with open('search_results_urls.txt', 'w') as filehandle:
for result_page in url_list:
filehandle.write('%s\n' % result_page)
print("---DONE---")
This is what we have got so far:
search_button = driver.find_element_by_id("nav-search-submit-text").click()
def search_amazon(item):
driver = webdriver.Chrome(ChromeDriverManager().install())
driver.get('https://www.amazon.com')
search_box = driver.find_element_by_id('twotabsearchtextbox').send_keys(item)
search_button = driver.find_element_by_id("nav-search-submit-text").click()
driver.implicitly_wait(5)
try:
num_page = driver.find_element_by_xpath('//*[@class="a-pagination"]/li[6]')
except NoSuchElementException:
num_page = driver.find_element_by_class_name('a-last').click()
driver.implicitly_wait(3)
url_list = []
for i in range(int(num_page.text)):
page_ = i + 1
url_list.append(driver.current_url)
driver.implicitly_wait(4)
click_next = driver.find_element_by_class_name('a-last').click()
print("Page " + str(page_) + " grabbed")
driver.quit()
with open('search_results_urls.txt', 'w') as filehandle:
for result_page in url_list:
filehandle.write('%s\n' % result_page)
print("---DONE---")
Incorporate an Amazon Search Result Pages Scraper in the Script.
As we’ve transcribed our function for searching our items as well as repeat through results pages, we wish to grab as well as save the data. For doing so, we would utilize an Amazon search result page scraper from the retailgators-code.
The extract function would use URL’s in the text file for downloading the HTML, scrape Amazon product data like pricing, name, as well as product URL. After that, place that into ‘search_results.yml’ files. Underneath the search_amazon() function, position the following:
source code: https://www.retailgators.com/how-to-scrape-amazon-results-using-python-and-selenium.php


IntroductionPrice scraping is an important tool, broadly used by the e-commerce companies to be competitive as well as get more sales.
Price matching and scraping helps the e-commerce companies understand the actual selling price of all the products on the competitors’ websites that helps them in tweaking their individual pricing to be competitive.
This is also broadly used by established and emerging players that are providing price comparison platforms to the consumers.Price Scraping ProcedurePrice data extraction or price scraping is performed by setting up customized web crawlers for fetching the product information from the competitors’ e-commerce websites.When the crawling is done, the scraped product data might contain different fields like website name, product name, brand name, and pricing.
This standardization is very important because the data fields could have symbols, special characters, or numbers – all might create problems during the matching.At Retailgators, we provide the scraped pricing data through different formats like CSV, JSON, or XML according to your preferences.
At this time, data from different websites are provided unique IDs to get identified separately through the matching algorithms.
A matching algorithm uses text-matching methods on the accessible input that are extracted product data as well as reference website data.


By using the Amazon scraping tool to scrape grocery delivery information will assist you to easily study your competition, keeping a record of important product information like prices and ratings, and spot emerging market trends.Below are the Steps for Scraping Amazon Grocery Delivery DataCreating an account on X-byte Cloud.Selecting the Amazon scraping tool for instance Amazon search results Scraper.Enter the list of input URLs.Execute the crawler, and download the required data.X-Byte Cloud's pre-built scrapers allow you to extract publicly available data from Google, retail websites, social media, financial websites, and more.
You can use your browser to access the scraper at any moment, enter the required input URLs, and the data will be delivered to you.Data Fields Scraped from Amazon Grocery Delivery DataUsing Amazon search result scraper, we can extract the below-given data fields:Product nameCategoryPriceReviewsRatingsDescriptionsASINSeller informationHow to Scrape Amazon Grocery Delivery Data?The Amazon Search Results Scraper from X-Byte Cloud is simple to use and allows you to safeguard data in the most efficient way possible.
A thorough explanation of how to execute the Amazon Search Results Scraper, which is available on X-Byte Cloud, can be seen below.Step 2: Add the Amazon Search Result Crawler to Account and Provide with Necessary Requirements.After making an account on X-Byte Cloud, go to the Crawlers tab and add the Amazon Search Results Scraper.After that, select ‘Add this crawler to my account.'
The main basic page, as shown under the ‘Input' tab, has all data fields:Crawler Name:Providing a name to your crawlers may help you distinguish between scraping operations.
Simply type in the domain you want to scrape into the input field and the scraper will handle the rest.Search Result URLsThen, throughout this data field, enter your target URLs.
Scraping can be accelerated by including the names of your competitors' brands.Number of Pages to ScrapeOn Amazon, you can choose the amount of search results pages to scrape.

Amazon helps you to provide services for the Prime Members.
Moreover, you can do competitor research, shopping comparison, or built an API for the project's app.Web Scraping helps you to easily solve data.Amazon product data scraping assists you to choose specific data you need to wish from the Amazon site from Spreadsheet or JSON file.
You can easily make an automated process, which runs on a weekly, daily, or monthly basis by updating data constantly.Amazon Web Scraping SolutionsAt Web Screen Scraping, we help you to provide complete solutions for Amazon web scraping like images, product features, names, and many more required details.To scrape data from Amazon, you need experience & professionals for putting up all the efforts in and logical manner.
From the big retail organizations, we constantly helping them in preparing directory, doing market research, as well as inventories of the most current products via tool for Scraping Amazon Product Listings.Finest & Structured Data for Amazon Data ScrapingObtaining Amazon Product datasets & directories, which are the latest, accurate, and scraped.
We help you to provide your customization features for scraping Amazon prices with product listing.
Web Screen Scraping, which helps to grow business provides quotes and competitive prices for the finest option.Why A Business Organization needs Amazon Scraper Tool?Amazon Data Scraper collects important data about the products like technical details, price range, sales rank, ASIN, etc.


The Global PVC Window Profile Market Research Report - Industry Analysis, Size, Share, Growth, Trends and Forecast Till 2026 gives an evaluation of the market developments based on historical studies and comprehensive research respectively.
The market segments are also provided with an in-depth outlook of the competitive landscape and a listing of the profiled key players.The comprehensive value chain analysis of the market will assist in attaining better product differentiation, along with detailed understanding of the core competency of each activity involved.
The market attractiveness analysis provided in the report aptly measures the potential value of the market providing business strategists with the latest growth opportunities.The report classifies the market into different segments based on type and application.
These segments are studied in detail incorporating the market estimates and forecasts at regional and country level.
The segment analysis is useful in understanding the growth areas and probable opportunities of the market.Final Report will cover the impact of COVID-19 on this industry.Browse the complete Global PVC Window Profile Market Research Report – Industry Analysis, Size, Share, Growth, Trends and Forecast Till 2026 @ https://www.decisiondatabases.com/ip/53045-pvc-window-profile-market-reportThe report also covers the complete competitive landscape of the global PVC Window Profile market with company profiles of key players such as:Alphacan SpAAluplast GmbHDeceuninckEpwin GroupEurocellPiva GroupProfine GroupRehauSalamanderSchucoVEKASEGMENTATIONS IN THE REPORT:By TypeTurn & Tilt WindowsSliding WindowCasement WindowOthersBy ApplicationResidentialCommercialBy Geography:North America (NA) – US, Canada, and MexicoEurope (EU) – UK, Germany, France, Italy, Russia, Spain & Rest of EuropeAsia-Pacific (APAC) – China, India, Japan, South Korea, Australia & Rest of APACLatin America (LA) – Brazil, Argentina, Peru, Chile & Rest of Latin AmericaMiddle East and Africa (MEA) – Saudi Arabia, UAE, Israel, South AfricaDownload Free Sample Report of Global PVC Window Profile Market @ https://www.decisiondatabases.com/contact/download-sample-53045The Global PVC Window Profile Market has been exhibited in detail in the following chapters –Chapter 1 PVC Window Profile Market PrefaceChapter 2 Executive SummaryChapter 3 PVC Window Profile Industry AnalysisChapter 4 PVC Window Profile Market Value Chain AnalysisChapter 5 PVC Window Profile Market Analysis By TypeChapter 6 PVC Window Profile Market Analysis By ApplicationChapter 7 PVC Window Profile Market Analysis By GeographyChapter 8 Competitive Landscape Of PVC Window Profile CompaniesChapter 9 Company Profiles Of PVC Window Profile IndustryPurchase the complete Global PVC Window Profile Market Research Report @ https://www.decisiondatabases.com/contact/buy-now-53045Other Reports by DecisionDatabases.com:Global PVC Modifier Market Research Report – Industry Analysis, Size, Share, Growth, Trends and Forecast Till 2026Global Polyvinyl Chloride (PVC) Resins Market Research Report – Industry Analysis, Size, Share, Growth, Trends and Forecast Till 2026Global Polyvinyl Chloride (PVC) Films Market Research Report – Industry Analysis, Size, Share, Growth, Trends and Forecast Till 2026About-Us:DecisionDatabases.com is a global business research reports provider, enriching decision makers and strategists with qualitative statistics.
DecisionDatabases.com is proficient in providing syndicated research report, customized research reports, company profiles and industry databases across multiple domains.Our expert research analysts have been trained to map client’s research requirements to the correct research resource leading to a distinctive edge over its competitors.



















